
About Me
Background
- PhD in Behavioral Psychology, University of Kansas (Derek Reed)
- Graduate Research Assistant, Center for Research Methods and Data Analysis (Paul Johnson)
- Postdoctoral Fellow, Virginia Tech (Mikhail Koffarnus and Warren Bickel)
- Assistant Professor, University of Kentucky College of Medicine
- Data Scientist, Advocates for Human Potential
Things I Do
Advocates for Human Potential
- Create and implement data pipelines, generate data insights via modeling, full stack app development
codedbx
- Serve as a research and statistical consultant, conduct analyses, and generate reports
- Build open-source tools: R packages (
beezdemand,beezdiscounting) and the R Shiny web appshinybeez - Built the 27-Item Monetary Choice Questionniare Automated Scorer
- Authored 70+ peer-reviewed publications
- More about me and my work at codedbx.com

Deep reflection

When confronted with some data, what do most behavior analysts or applied behavioral scientists reach for?
Visual inspection?
Descriptive statistics?
Maybe if you’re feeling brave, a statistical test?
T-test?
ANOVA?
Regression?
A small simulated dataset
- Imagine measuring some behavior over time for multiple subjects. Each subject is in a different condition and we want to model what affect the condition has on behavior across sessions.

If we are feeling brave…
We could fit a linear regression by condition, and then compare the slope and intercept between conditions
Typical linear regression: \(y = Intercept + Slope * x\)
Looks pretty good…
- What does our output say?
Call:
lm(formula = response ~ session + condition, data = dat)
Residuals:
Min 1Q Median 3Q Max
-4.4349 -1.5101 -0.1005 1.4455 4.6365
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 24.67256 0.47151 52.326 < 2e-16 ***
session -0.48729 0.03254 -14.976 < 2e-16 ***
condition2 1.95819 0.45958 4.261 4.16e-05 ***
condition3 2.64218 0.45958 5.749 7.39e-08 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 2.055 on 116 degrees of freedom
Multiple R-squared: 0.6914, Adjusted R-squared: 0.6834
F-statistic: 86.64 on 3 and 116 DF, p-value: < 2.2e-16

- We know how the overall effect of condition affects behavior across session, but that’s all we really know. We don’t know about how each subject responds and their trajectory.
Ok, easy. Let’s just fit a line to each subject!

- Both of these are considered fixed-effect only models because the parameters we estimate are fixed either across subjects or fixed within subjects.
Ok, easy. Let’s just fit a line to each subject!
Fixed effects definition
Fixed effects are assumed constant in the broader population from which the observed data are drawn. The sample data are used to produce estimates of these parameters, and the resulting estimates have with some degree of imprecision (i.e., standard error).
Another way to think about it is a “pooled” model (all the data points are pooled together; i.e., “fit to group”) vs. no pooling model (each subject has its own data points; i.e., “two-stage”). The latter considered “amnesic” models because they ignore information from other subjects (see McElreath, 2020).
Overfitting risk: no borrowing of strength → noisy subject-level slopes
Inflated uncertainty: two-stage standard errors often understate uncertainty for population questions
Let’s see them in action
One flavor that we can specify is what is called a random intercepts model (or a random effects model).
Notice we use the lmer package here instead of the lm package. In this code, we are specifying our outcome as a function of session and condition (just like in the fixed-effects only model), but now we are specifying we want the intercept to be random (i.e., different for each subject).

Let’s see them in action

However, this model assumes that the slope is constant across subjects, so we may want to add a random slope term to the model.
Let’s see them in action
In this code, we are specifying our outcome as a function of session and condition (just like in the fixed-effects only model and our random intercepts model), but now we are specifying we want the intercept and the slope (session) to be random (i.e., different for each subject).

Let’s see them in action

Fixed vs. Random Effects (Simply)
Fixed effect
An effect that is constant across individuals (e.g., a treatment effect assumed to be the same for everyone). It’s something we explicitly estimate for the population.

Random effect
An effect that varies across individuals or clusters. It’s not a single estimate but a distribution. For example, each subject can have their own intercept (starting level) or slope (trend), and these are assumed to be drawn from some population distribution. The larger the random effect, the model is capturing more variability between individuals/groups.

Fixed vs. Random Effects (Simply)
\(y_{ij} = \beta_0 + \beta_1 \, \text{time}_{ij} + u_{0j} + u_{1j}\,\text{time}_{ij} + \varepsilon_{ij}\)
- (\(\beta\)): fixed effects (population)
- (\(u\)): random effects (subject/cluster deviations)
- (\(\varepsilon\)): residual/error
Metaphor
Fixed effects = the overall recipe
Random effects = each chef’s personal twist on that recipe.
We model the general effect and the individual deviations.
Ok, but why should I care?
What you mean to ask is when should I consider using a mixed effects model?
Take this scenario for example (from DeHart & Kaplan, 2019):
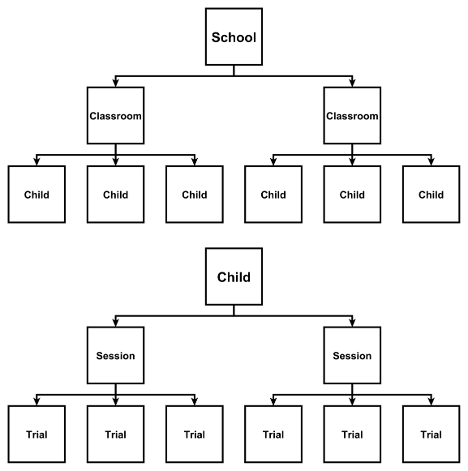
Or this scenario (from Krzywinski et al., 2014):

Hierarchical (nested) data structure: Illustration of three-level hierarchy (Level 3 = school/individual, Level 2 = classrooms/sessions, Level 1 = children/trials). In this illustration, each school (or individual) includes multiple classrooms (or sessions), and each classroom or session has multiple observations (children or trials). Such nesting means observations within a classroom are (probably) more alike than observations from different classrooms. Likewise, observations within a session are (probably) more alike than observations from different sessions.
However, not all data are purely nested. Sometimes, the same observation belongs to multiple grouping factors that are not contained within each other — for example, students nested within both classrooms and teachers, where teachers teach multiple classrooms, and classrooms have multiple teachers across time. This is known as a crossed-effects (or non-nested) design.
Mixed-effects models can handle these too — by estimating random effects for each grouping factor (e.g., classroom and teacher) simultaneously, recognizing that variability arises from both sources independently.
Modeling crossed factors example:
\(y_{it} \sim \beta_0 + \beta_1 \text{time}_{it} + (1|\text{student}_i) + (1|\text{teacher}_t)\)
(Students and teachers are crossed; each contributes its own random intercept.)
Example: Dehart & Kaplan (2019)

Example: Dehart & Kaplan (2019)

Example: Dehart & Kaplan (2019)
For more, see the full paper (also available at codedbx.com)

Applications: Behavioral Economic Demand

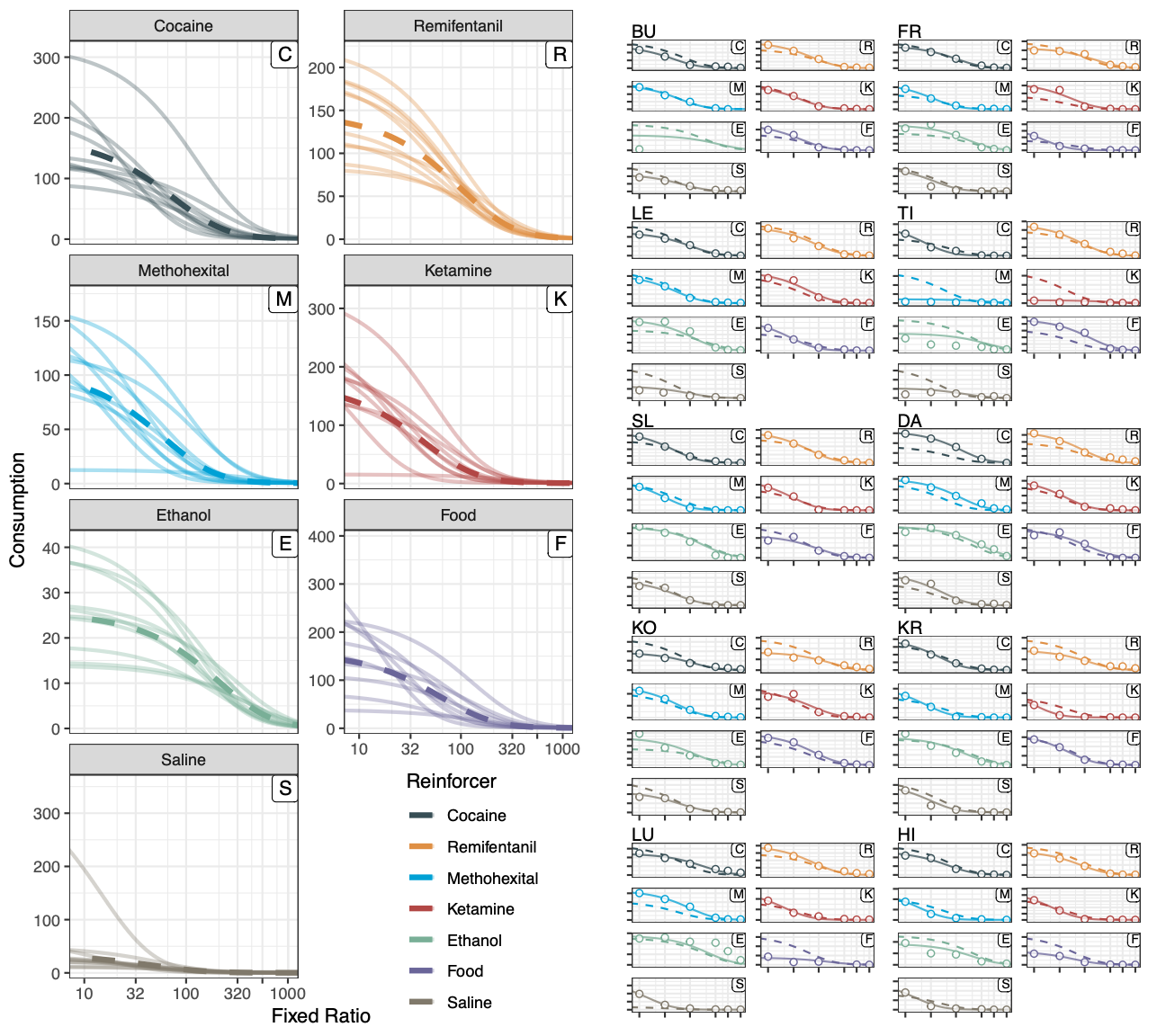
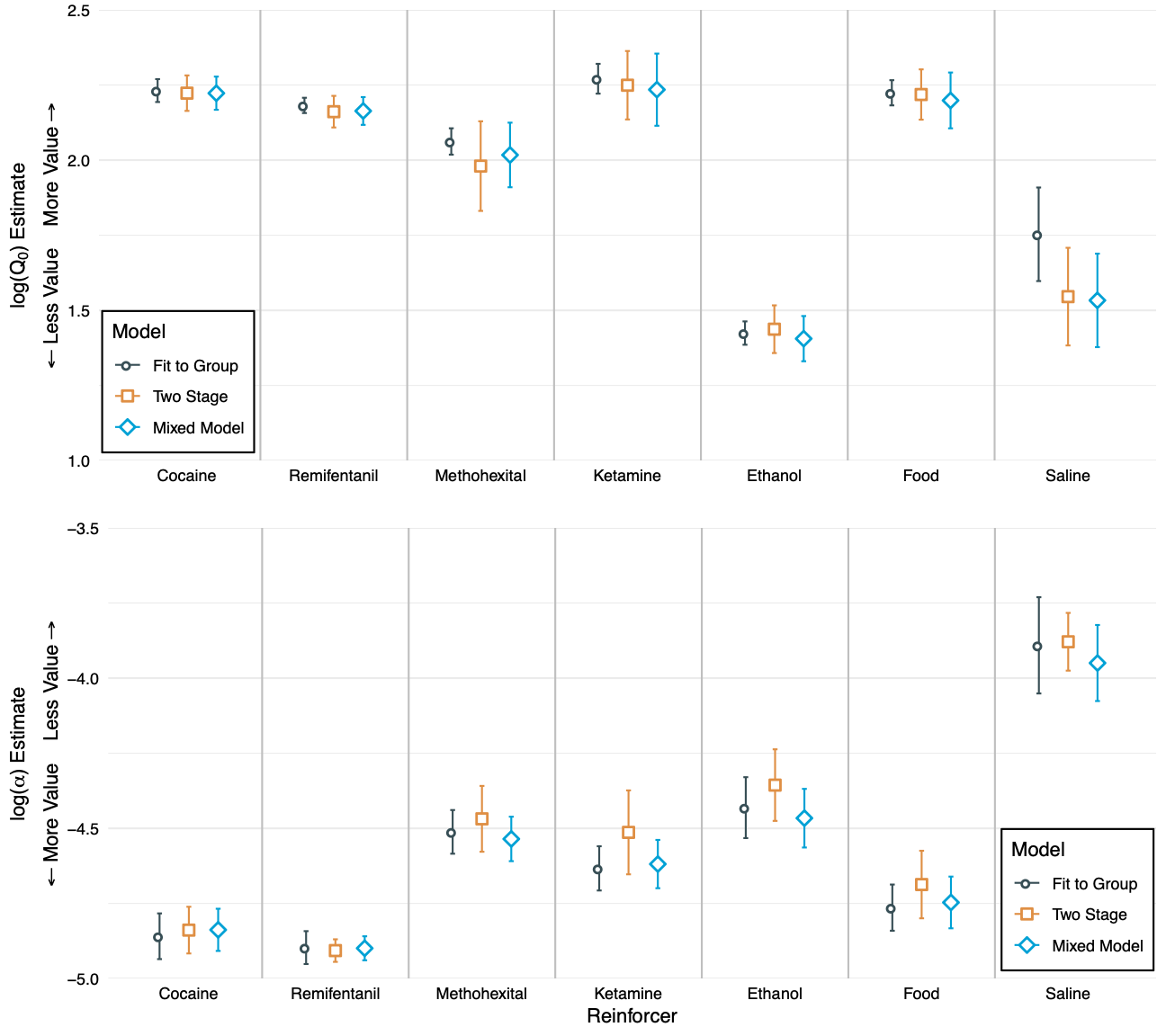
Applications: Behavioral Economic Demand
For more, see the full paper (also available at codedbx.com)

Further Resources
R packages
lme4nlmeglmmTMBmultilevelbrmsbeezdemand
scdhlmThe
scdhlmpackage PDF (Hedges et al.) includes multiple examples of analyzing single-case data (e.g., Laski dataset) and is a great resource for SCED researchers (scdhlm: Estimating Hierarchical Linear Models for Single-Case Designs).

